This Looks Like That: Deep Learning for Interpretable Image Recognition

Model interpretability is a topic in machine learning that has recently gained a lot of attention. Interpretability is crucial in both the development and usage of machine learning models. It helps the developers understand why particular mistakes are made and how they can be improved. It also makes it easier for the end user to see what factors lead to a final decision rather than relying on a vague final score or probability.
In this regard, many specialists recommend using models that are inherently interpretable, e.g. decision trees or Explainable Boosting Machine (EBM) as they gain comparable results relative to more complex models and are transparent as opposed to black-box models.
However, such additive models are not applicable to all problems. In the computer vision realm for example, deep neural networks are by far the most promising solution to object detection, segmentation, etc. but lack interpretability.
There has been some research for explaining the decisions of deep neural networks. Such posthoc analysis fits a model to a trained model and therefore does not capture the true decision process.
In this article, I will be summarising the work of Chen et. al where an interpretable deep neural network is introduced. Unlike other neural networks, this model has the capability to explicitly give reasoning for its classification decisions by showing what parts of the input it thinks are similar to the training images.
Motivation and Objective
How do we as humans identify that a certain image is of a penguin and not a table or a parrot? Our brains are able to scan the image and compare the penguin's head, body shape, colour, etc. with the corresponding body parts of other penguins it has seen in real life or virtually. It also makes the same comparisons with other animals and objects it has seen before and concludes that the picture is most similar to a penguin. Our brain uses these seen instances as prototypes and assigns a similarity score between the image in question and each prototype.
Can a machine learning model be trained to do the same?
Enabling the neural network to reason in the same fashion is the goal of this study. The authors introduce prototypical part network (ProtoPNet) which learns to dissect the training images into prototypical parts, e.g. the penguin head, beak are considered as identifiable prototypes for the class penguin. The model then computes a weighted summation of the similarity scores between different parts of the input image and the learnt prototypes for each class. With this part of the image looks like that part of the training image approach, the model is transparent and the interpretation reflects its actual decision process.
ProtoPNet Architecture
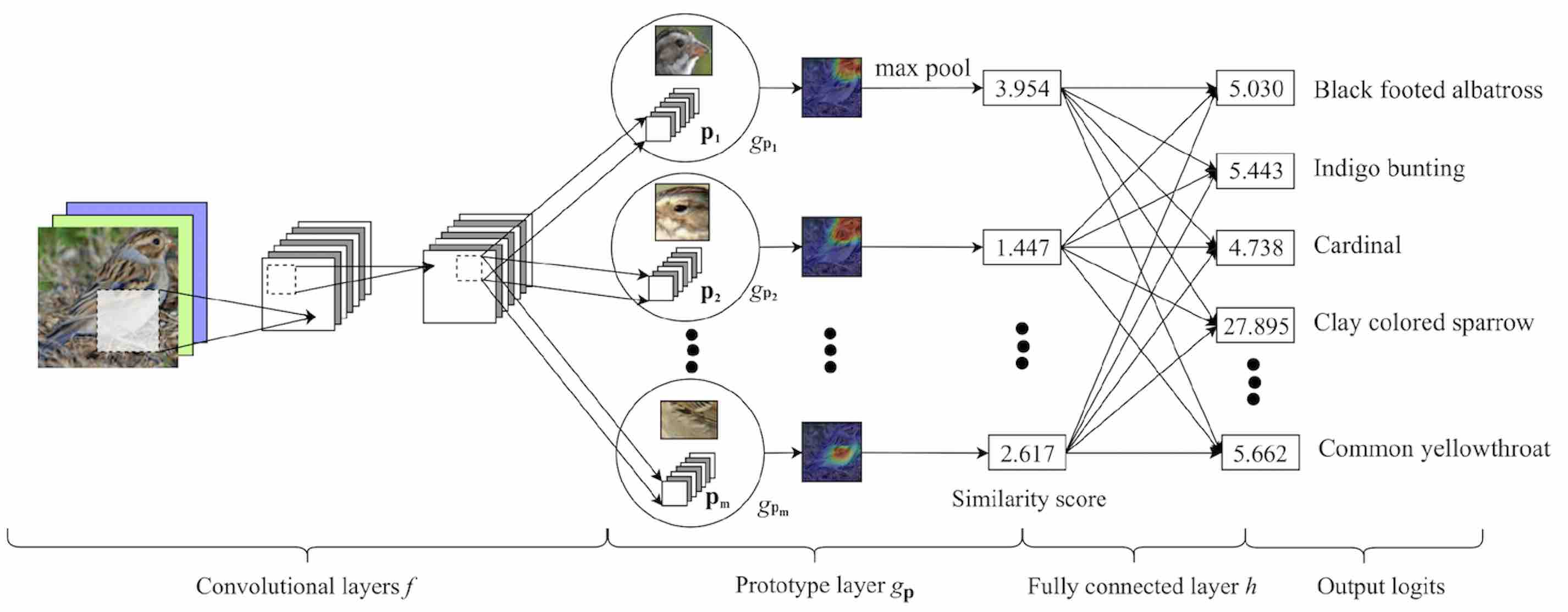
The proposed ProtoPNet uses a conventional convolutional neural network (CNN) such as VGG-16, VGG-19, ResNet-34, which has been pre-trained on ImageNet, followed by two additional $1 \times 1$ convolutional layers. The key element in this network is the prototype layer $g_p$ that comes after the CNN and is in charge of comparing the input image patches with some learnt prototypes. $g_p$ is then followed by fully connected layer $h$.
Fig. 1 (from paper), shows this architecture with an example. The input image of a clay colored sparrow, is split into patches which are mapped to a latent space by passing through the convolutional layers. The learnt prototypes $p_j$ are mapped to the same space and represent specific patches in the training set images. If you are familiar with NLP, this mapping is similar to embedding the input words to a vector space where words with similar meanings are closer to each other.
Then, for each input patch and each class, the euclidean distance between the latent representations of the patch and the class prototypes ($p_j$) are computed and inverted to similarity scores. The higher the score, the stronger the chance of a prototypical part being present in the input image. These similarity scores can be seen as an activation map where the areas with higher activity indicate a stronger similarity. We can upsample this activation map to the size of the input image in order to visualise where these areas are in the form of heat maps. This heat map is then reduced to a single similarity score using a global max pooling. For example, in Fig.1 the similarity between a learnt clay colored sparrow head prototype ($p_1$) and the head of the clay colored sparrow in the input is 3.954 and the similarity score between that input patch and a Brewer’s sparrow head prototype ($p_2$) is 1.447 indicating that the model finds the input image patch to be more similar to the first prototype than the second.
Finally, the similarity scores are passed to a fully connected layer to produce output logits which are normalised using a softmax function.
Training ProtoPNet
For training the proposed network, the CUB-200-2011 dataset which is a dataset with 200 bird species was used. For the prototype layer, a fixed number, 10 prototypes per class, was considered for learning the most important patches in the training dataset.
In order for the model to learn which prototype patches among the training data of each class are most differentiating, a meaningful latent space needs to be learnt where the semantically similar image patches, e.g. different patches of male peacock feathers are mapped to the same area.
This can be seen as a clustering problem where the goal is to select features, i.e. patch representations in a way that patches belonging to the same class are close to one another and patches from different classes are far away and easily separable.
We can enforce such separation by penalising the prototype patches that are found to be very similar to patches of other classes. For example, a patch that includes a tree branch should be penalised if selected as there can be pictures of birds on tree branches in any of the classes.
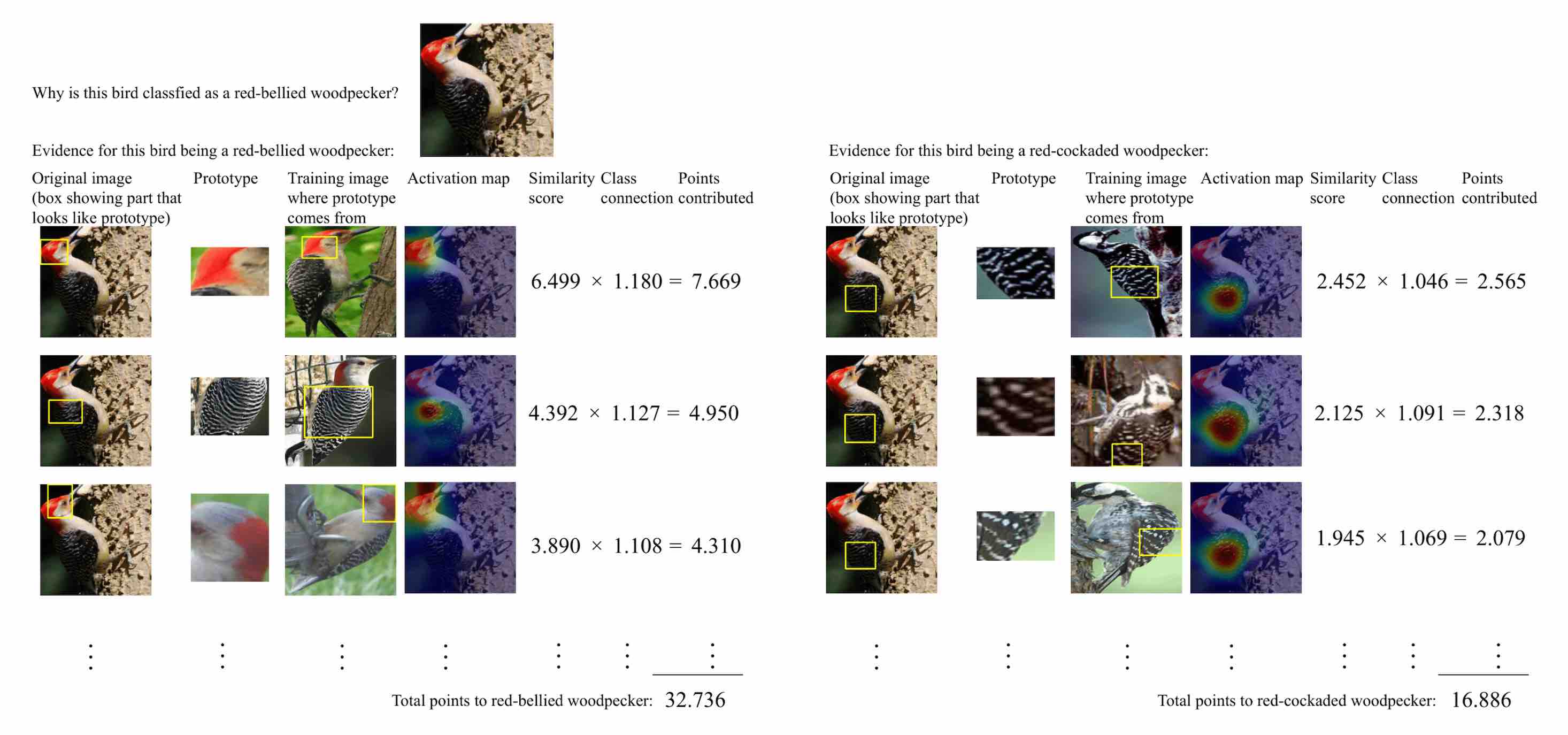
Fig.2 shows an example of classifying a test image of a red-bellied woodpecker after training. Latent features, $f(x)$, are computed from the convolutional layers and then a similarity score between $f(x)$ and the latent features of each 10 learnt prototypes of each class is computed. In Fig.2 two of these similarity computations are shown. The left image shows the similarity scores of three prototype images of the red-bellied woodpecker class along with the upsampled heat map that shows the areas in the original image that are strongly activated by the similarity computation. These similarity scores are then multiplied with the class weights and summed to give a final score of the input image belonging to that class. The same process happens in the right image but for a red-cockaded woodpecker. Comparing the final scores of the two classes, we see that the model seems more confident that the test image belongs to the red-bellied woodpecker.
Results
A number of baseline models (CNNs without the prototype layer) were trained using the same training and testing dataset (with the same augmentation) used for ProtoPNet, and as seen in Table.1, the results are very similar which verifies that interpretable models are a good alternative to black-box models.

Conclusion
In this article, I explained ProtoPNet, a deep neural network that is able to reason about classifying input images in a similar fashion to humans. Such transparency is especially important in high stake applications such as medical image classification where a single score of whether there is a brain tumor in a given MRI is not sufficient.
I hope you enjoyed learning about interpretable deep learning models and try to implement them in your own projects. If you like reading about machine learning, natural language processing and computer vision, follow me on twitter for more content!