Extracting Training Data from Large Language Models

Language models (LM) are machine learning models trained on vast amounts of text to learn the intricacies and relationships that exist among words and concepts; in other words, the distribution over words and sentences. Generally, it has been seen that the larger these models are the more powerful they become at handling various natural language tasks that they may not have even been trained for.
We have all heard about GPT-3 developed by OpenAI in June 2020 and have seen various demos and articles about its size and performance.
Language models like GPT-3 and its predecessor GPT-2 use publicly available data on the world wide web as training data. The issue of data privacy may not be a big concern when it is already published and readily available. However, it can be problematic when the data used for training the language model is private, contains personally identifiable information (PII) and yet the data can be retrieved using adversary attacks.
In this article, I will be summarising the methods used by Carlini et. al to extract training data from GPT-2. They show that using simple adversary attacks one can query a black box language model for memorised training data.
Studied Language Models
For this study, the authors have used different variants of GPT-2 with a main focus on the biggest version, GPT-2 XL with 1.5 billion parameters. The dataset used for training this model was scraped from the internet, cleaned of HTML, and de-duplicated. This gives a text dataset of approximately 40 GB.
Memorisation
Memorisation is a necessary element in our learning process as humans. We need to memorise some information in order to be able to generalise our learning. Neural networks are not very different in this regard. For example, a neural network model needs to memorise the pattern of postal codes in California before generating a valid postal code when given a prompt such as "My address is 1 Main Street, San Francisco CA".
Although such an abstract form of memorisation is needed, memorising exact strings of training data especially those containing PII can be problematic and ethically concerning.
It is generally believed that memorisation of training data is a result of overfitting. This study shows that this is not always the case and although LM models such as GPT-2 that was trained on a large dataset over as few as 12 epochs does not overfit, the training loss for some data samples are anomalously low. This low training loss makes the model prune to memorising those training examples.
Text Generation Methods
To query the LM for training data one has to a) generate text from the LM and b) infer whether the generated sample is a member of the training data. Language models generate text by iteratively sampling tokens, $x_{i+1}$ from some distribution conditioned on the $i$ previously selected tokens. This sampling ends when some stopping criterion is reached.
A number of different text generation methods are considered in this study which mainly differ in their sampling strategy, i.e. a greedy sampling method which chooses the tokens that have the highest likelihood compared to an exploration based sampling method that allows for a more diverse output.
Membership Inference Methods
Once text is generated from the LM, some measure is needed to infer whether each sample was in the dataset or not. This is called membership inference and there are different ways to implement it.
One way is by measuring the perplexity of a sequence. A low perplexity says that the model is not perplexed or confused by the sequence and if it predicts a high likelihood for the same sequence, it could be indicative that the sequence was memorised from the training data.
Another approach is by comparing the predicted likelihood of a sequence by the LM in question with another LM. The idea here is that if the predicted sequence is not memorised and the predicted score is high simply because the sequence of tokens makes logical sense then the other model that was trained on a different dataset should also predict a high occurrence likelihood for the same sequence. Therefore, a sequence with an unexpectedly high likelihood from GPT-2 compared to another LM can be a signal for memorisation.
Results
The authors generate 200,000 samples using different text generation strategies. Then, for each membership inference method, find the top 100 samples. This gives a total of 1800 samples of potentially memorised content which is verified manually through Google search and directly querying GPT-2 (after being granted access by OpenAI researchers).
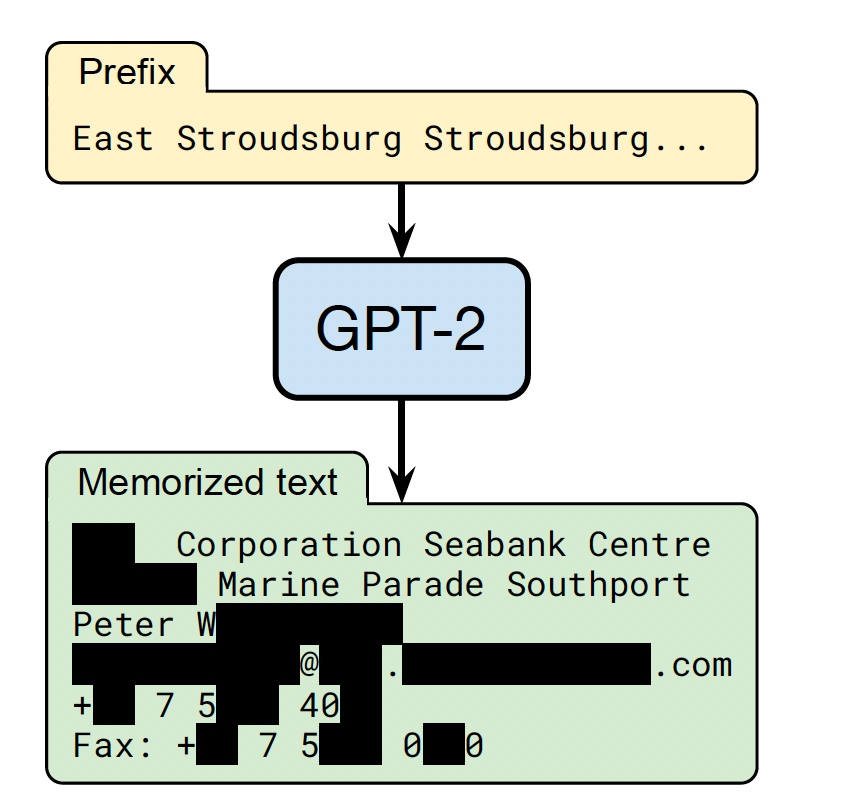
This results in an aggregate true positive rate of 33.5%. Most memorized content is fairly canonical text from news headlines, log files, entries from forums or wikis, or religious text. However, significant information on individuals such as addresses and telephone numbers were also found. Fig.1 shows an example of such memorised data. The PII are blocked out for privacy reasons.
The study also investigated the effect of the number of repetitions of a string in the training set and the size of the model on memorisation. It is found that a minimum frequency of 33 of a certain string in a single document seems to make the model prone to memorising that string and as the model gets bigger, memorisation increases.
Conclusion
This work was a proof of concept that large language models although do not overfit, still memorise some unnecessary information from the training set that may contain private information. Although the dataset for GPT-2 was scraped from the web and therefore may not have been "private", it is still concerning that black box models may memorise data that can be extracted given the appropriate prompt. This is especially problematic for when the data is later removed from the web or never was released but are exposed through black box models.
Some data curation or privacy measures, e.g. differential privacy is needed to ensure that the data does not contain sensitive information but in the case of large datasets there seems to be room for improvement and innovation to ensure security across all data points.
Although this study was submitted after the release of GPT-3 (December 14, 2020), the authors have not mentioned why they chose to focus on GPT-2 instead. However, they did compare the amount of content memorised by GPT-2 XL and its medium and small version with 334 and 124 million parameters respectively. This comparison showed that the XL model memorised 18 times more information. With this, it is expected that GPT-3 wich is ~100 times larger than GPT-2, has more data memorised.
I hoped you enjoyed learning about this study. If you like to read more about machine learning, natural language processing and computer vision, follow me on twitter for more content!