Learning Dynamic Belief Graphs to Generalize on Text-Based Games

In this post I am going to discuss a very interesting paper on the fusion of graph transformer networks and reinforcement learning (RL). This paper proposes a graph-aided transformer agent (GATA) that can learn how to play text-based games from scratch. GATA forms a graph that represents the game entities and dynamics. The agent updates its knowledge or belief of the game through a combination of reinforcement and self-supervised learning and learns how to take effective actions. The main objective of this study is to have the agent plan and generalise its actions solely from raw text as opposed to previous work which mainly rely on prior knowledge of the environment available through hard-coded rules and heuristics.
Problem layout
In text-based games the user interacts with the environment through written commands, for example, the user types go north or dice carrot to take different actions. There are various factors that make this a hard learning problem such as partial observability-when the agent does not have a full priori model of the environment- sparse rewards and long term dependencies between words in the text.
The authors use TextWorld which is a Python library with a list of text-based games designed for RL research with the flexibility to add/modify games. For the purpose of this study, a set of choice-based games with different difficulty levels have been created. All games have a cooking theme where the player has to discover a cooking recipe. The recipe consists of a list of tools and ingredients that can be found in various locations of the environment and the game is won once all the items are found and processed as instructed, e.g. dice carrot, fry, etc.
Text-based games can be represented with dynamic graphs $\mathrm{G}_t = (\mathrm{V}_t, \mathrm{\epsilon}_t)$. Where the vertices $\mathrm{V}_t$ represent entities, e.g. the player, locations, items and the state they are in, e.g. chopped, sliced, open, closed. The edges $\mathrm{\epsilon}_t$ represent the relation between entities at time $\it{t}$ : north_of, left_of, in, for example, the kitchen is south of the garden. You can think of the graph as an adjacency matrix with each entry ${\it{(r}, \it{i}, \it{j)}}$ indicating the strength of connectivity between two entities $ \it{i}$ and $\it{j}$. In this study the graph is instantiated with values between $-1 $ and $1$ and the agent has access to the corpus used in the game but has to learn the structure and relation between locations, items, ingredients on its own.
Introducing GATA
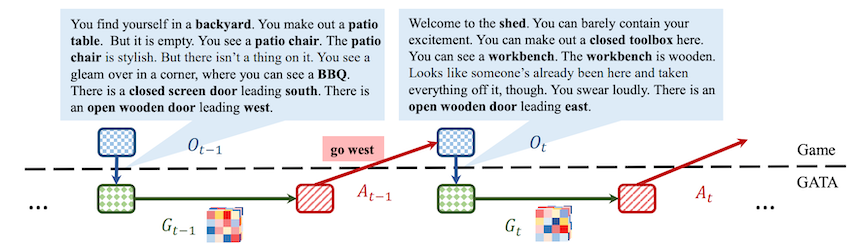
The goal is to use a transformer-based neural agent that can interpret the graph states at every time step for selecting its next action. The figure below (taken from the paper) shows a snapshot of the agent's interaction with the environment. The top blue coloured boxes is the game engine, the bottom boxes represent the agent. As the figure shows, at time point $\it{t-1}$ the agent takes action $\mathrm{A}_{t-1}$ which leads to observation $\mathrm{O}_t$. The agent updates its belief of the graph by using this observation along with the graph's previous state $\mathrm{G}_{t-1}$.
GATA's components

1- Graph Updater
As shown in Fig.1, at time $\it{t-1}$ the agent goes west which leads it to the shed where it finds a toolbox a workbench and an open door leading east. Based on this observation the graph updater updates the graph, i.e. connects the node representing the backyard to all the locations and objects it relates to such as the patio table, chair, BBQ, the shed.
The left green box in Fig.2 (taken from the paper) shows the process of updating the graph which can be broken down into 4 steps:
1- Text observations and graph states at time ${t-1}$ are converted to vector representations by passing through encoders
2- The encoded observations and graphs states are aggregated using a recurrent neural network (RNN) $\mathrm{f}_{\Delta}$. This produces $\mathrm{\Delta}{g}_{t}$
3- The graph's hidden state, $\mathrm{h}_{t-1}$ which can be thought of as the game's memory, enters another RNN along with $\mathrm{\Delta}{g}_{t}$ and produces $\mathrm{h}_{t}$
4- $\mathrm{h}_{t}$ passes a multi layer perceptron (MLP) $\mathrm{f}_{d}$ to be decoded into an adjacency matrix $\mathrm{G}_{t}$
The graph updater is pre-trained using two self-supervised methods and is fixed when GATA interacts with the game. I briefly discuss the intuition behind the two pre-training algorithms below. The goal of these methods is for the graph updater to have sufficient information about the environment and to minimise the uncertainty between the belief graph $\mathrm{G}_{t}$ and the next observation $\mathrm{O}_{t}$.
Observation Generation (OG):
As previously mentioned, the agent has access to the game's text corpus. This corpus is used to train a sequence to sequence model that predicts the next word following a series of observed words. In other words, given a graph state $\mathrm{G}_{t}$, action $\mathrm{A}_{t-1}$ and partial observation $\mathrm{O}_{t}$, e.g. "you see yourself in the backyard, to your right is a ---", the model predicts the following word based on the connections the graph has at time ${t}$. This helps the graph updater learn the relation between the entities so when the agent plays the game it can provide the action provider with an accurate belief graph ${G}$.
Contrastive Observation Classification (COC):
The intuition here is that we want to be most certain about $\mathrm{G}_{t}$ leading to a specific observation $\mathrm{O}_{t}$. Because this certainty verifies that the graph updater has learnt the environment well and therefore can help the action taker take highly effective actions. To achieve this, an algorithm known as contrastive learning (CL) is used. You can think of CL as a similarity detector where it compares the inputs to one another until it finds a match.
In this paper new observations were generated by adding noise to the corpus text observations and then a model is trained to differentiate between the encodings of the true and corrupted observations conditioned on $\mathrm{G}_{t}$ and $\mathrm{A}_{t-1}$.
2- Action Selector
The action selector, which is trained and optimised using Q-learning, uses the updated belief graph $\mathrm{G}_{t}$ and observation $\mathrm{O}_{t}$ to choose the next move. Its selection process as seen in Fig.2 can broken down into three steps:
1- Encoding: Similar to the graph updater, the text observations and graph states have to be converted into vector format. To this end, a relational graph convolutional network (R-GCN) and a transformer encoder are used for the graph states and text instructions respectively
2- Representation Aggregator: The vector representations from step 2 are combined using a bidirectional attention-based aggregator. An attention-based method in two directions (from the text to the graph and vice versa), helps with focusing on what is most relevant.
4- Scorer: Ranks all candidate actions based on the aggregated representations using an attention-based MLP
Results
The authors ran experiments to see if 1) Does the graph updater component help GATA achieve higher reward scores on games the agent has never interacted with? and 2) Does GATA outperform other models that have access to the game's ground-truth graph representations?
Around 500 text-based games with varying difficulty were used to compare the performance of GATA with other models and on average GATA outperformed the baseline methods by 24%. Please refer to the paper for details on the comprehensive tests run.
Conclusion
I hope this article helped you build an intuition on how GATA works. Such self-learning agents can be a powerful tool in improving human-computer interaction by interpreting natural language in a more sophisticated and accurate manner.
If you enjoy learning about BCIs, machine learning and natural language processing follow me on twitter for more content!